「AIモデルによる自動ラベリングプロジェクト」は、AIを活用した言語モデルにより、文書へのタグ付け(ラベリング)作業を自動化することを目的としています。本プロジェクトの中心には、ラベル付きデータベースから関連文書を検索するために最適化された検索システムが搭載されています。単純なキーワードマッチングに依存するのではなく、文書の意味を理解するセマンティック検索を活用し、意味的に類似した文書を抽出することで、より適切なラベルの予測に必要な文脈を提供します。このアプローチにより、モデルは過去にどのように類似文書がラベリングされたかを参照しながら、より的確な判断を下すことができます。
このラベリング自動化により、大規模なデータセットに対する手作業の負荷を大幅に軽減するとともに、ラベリングの一貫性を向上させることができます。特に、法務、医療、研究、エンタープライズデータ管理など、正確な分類が求められる分野において高い効果を発揮します。また、モジュール設計により「人による確認(ヒューマン・イン・ザ・ループ)」の導入も可能であり、品質保証の水準に応じて柔軟に対応できるスケーラブルなソリューションとなっています。
現在の文書管理システムは、検索機能の効率性と精度が低下しており、ユーザーが最も関連性の高い情報を迅速に取得することが困難になっています。さらに、関連文書間の意味のある関係性を特定・維持することが困難なため、データアクセスが断片化し、大規模環境でのユーザビリティが低下しています。これは生産性を低下させ、重要なコンテンツを見逃すリスクを高めます。


本プロジェクトでは、いくつかの重要な課題に直面しました。主な問題の一つは検索精度の低さであり、システムが関連性の高い文書を十分に返せないことが多く、ユーザーの信頼性や効果性が低下しました。効率的でない検索アルゴリズムによる処理の遅延も課題で、応答時間の長さが全体の生産性に悪影響を及ぼしました。さらに、文書間の連携不足も大きな問題で、関連文書同士の関係を認識・保持できず、情報が断片化してしまいました。最後に、情報アクセスの困難さもユーザーの包括的な情報取得を妨げており、文書の構造的な関係性の欠如がナビゲーションの難しさを引き起こしていました。

これらの課題に対応するために、いくつかの主要な解決策を実施しました。まず、文書をノード、関係性をエッジとして保存するグラフデータベースを導入し、相互に関連するデータをより効率的かつ意味のある形で表現できるようにしました。これに加え、最適化された関係マッピングを行い、グラフ構造を活用して複雑な文書間の関係性を捉え、関連性や文脈に沿った検索結果の取得能力を向上させました。また、ユーザーがデータベースを直感的にクエリし、検索結果を明確かつ正確にナビゲートできるユーザーフレンドリーなインターフェースを設計しました。最後に、グラフ構造を活用したインテリジェントなクエリ機構を組み込むことで、検索ロジックを強化し、より高速かつ高精度な検索結果を実現しました。






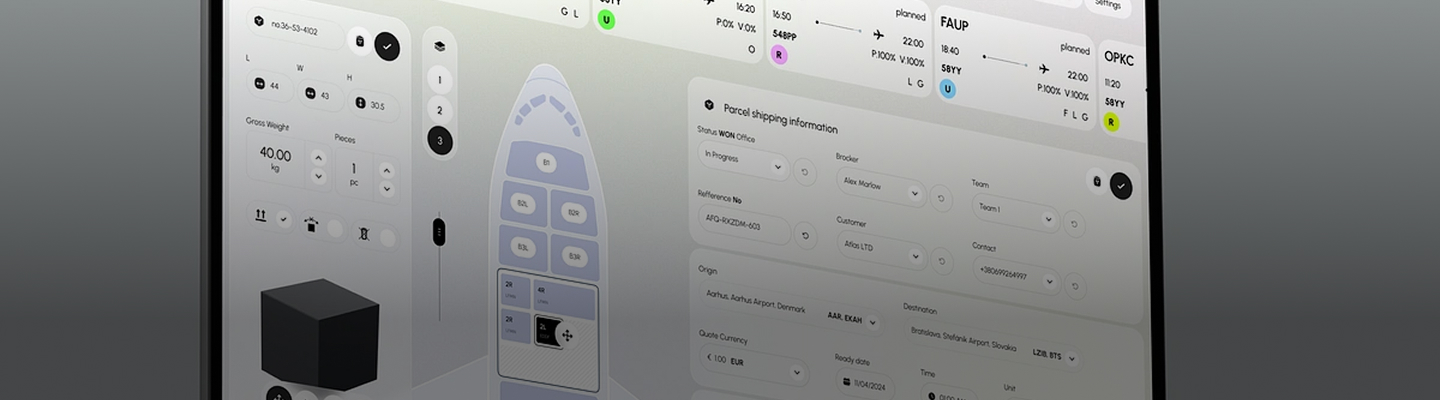
システムエラーのトラブルシューティングにかかる時間を大幅に短縮するだけでなく、可視化ツールの統合は、エンジニアが複雑なシステムと関わる方法を大きく変革しました。以前は、システムクラッシュの原因となった特定のファイルを特定するなど、障害の根本原因の特定には数十分、時には数時間もかかっていました。高度な可視化により、同じタスクが数秒で完了できるようになりました。システムの構造と動作を明確かつインタラクティブに視覚化することで、応答時間の改善だけでなく、システム全体の透明性と理解度も向上します。
このツールは、AIと論理分析を活用して、ソースコードと設計ドキュメントの両方を詳細に調査します。手作業では容易に追跡できない隠れた関係や依存関係を明らかにします。対象システムに馴染みのないユーザーでも、関連するソースファイルや関連ドキュメントを迅速に特定できます。さらに、これらの要素がどのように相互作用するかを明らかにし、その役割やつながりを即座に把握できます。この機能は影響分析や障害診断に非常に役立ち、チームは 1 つのコンポーネントの変更やエラーが他のコンポーネントにどのような影響を与えるかを迅速に評価できるため、調査プロセスの速度と信頼性が向上します。